Cache Memory
Mini-Lecture
Bob BrownSchool of Computing and Software Engineering, Southern Polytechnic State University
Copyright © 1999 by Bob Brown
Let's run through an example of using a cache memory. This is similar to the direct-mapped cache that's used as an example in Tanenbaum. [TANE99] We are going to use a very concrete example to give you the flavor of how a cache works. You can generalize from this example to caches of other sizes. (This will be easier to study of you print at least the first page so you can refer to the diagrams as you read.)
This particular cache has 2,048 "lines" each of which can hold 32 bytes (not bits) of data. There are also some tag bits, a "valid" bit, and a "dirty" bit, which we didn't mention in class.
Note that 2,048 lines of 32 bytes each makes 65,536 bytes. This is a 64K byte cache. That's small for the current time, but it'll do fine for an example.
There's a sketch of the cache below, with one of the "lines" blown up so you can see how things are arranged. The cache is a memory with 2048 cells. Each cell has 274 bits. There are two bits for "valid" and "dirty," 16 bits for "tag" and 256 bits (32 bytes) for data. The cache considers each cell to be made up of fields as shown, but it's really all one memory with very wide, bit-addressable cells.
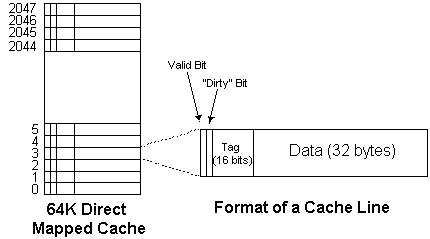
The memory subsystem that contains this cache has a design maximum of 4GB of RAM. This means it has a 32-bit address. For purposes of addressing memory, each address is just a 32-bit number. However, for purposes of searching the cache, we think of the addresses generated by the CPU as being divided into three fields, as shown below. The meanings of the fields will become clearer as we "process some data" through the cache.

Let's go through reading and writing several memory values and observe how the cache interacts with the main memory and the CPU.
Initialization: When the memory system is initialized, perhaps when the computer is powered on, or reset, the valid bit of each cache entry is set to zero. Nothing else in any entry needs to be changed. You'll see why as we go along.
CPU Requests Data: Suppose the first memory request the CPU makes is for a byte of data from location 196,668. (I made that number up; it's a little bit more than 192K.) In hex this number is 3003C. Converting to binary we get 0011 0000 0000 0011 1100. We can make this a 32-bit number by adding zeroes on the left. To make it easy to see what's going on, we also break it up according to the "fields" in the diagram above, instead of grouping the bits in fours. Afterwards, it looks like this:
0000000000000011 00000000001 11100Each line in our cache can hold 32 bytes, so we want to transfer 32 bytes from memory to the cache, and at the same time provide the requested byte to the CPU. We perform a memory read of 32 bytes at address 0000000000000011 00000000001 00000. This is the same as the number above but with the last five bits, the byte number, set to zero. All 32 bytes get sent to the data area of cache line 1, and byte 28 out of the 32 -- that's byte 11100 -- also gets sent to the CPU.
Simultaneous with storing the data, we set the valid bit for line one to 1 indicating that it contains valid data, the dirty bit to zero (you'll see why in a moment) and the 16-bit tag field to 0000000000000011 -- the "tag" part of the generated address. We have satisfied the CPU's request and loaded a block of data into a line of our cache.
Another CPU Request: Now the CPU requests a byte from address 196,669. This isn't surprising; it's an example of spatial locality of reference. In binary, 196,669 looks like 0000000000000011 00000000001 11101. We examine line one of the cache and find that the valid bit is a one. That's not quite enough, though. We also compare the 0000000000000011 of the tag part of the address with the tag field from the cache. We will see why shortly. Since they're equal, we can proceed and deliver byte 29 -- that's byte 11101, to the CPU. All this happened very fast because all the activity was within the cache. This is a cache hit.
The CPU then asks for bytes at addresses 196,670 and 196,671. These two requests are also satisfied from cache line one.
Another Cache Miss: Now the CPU asks for address 196,672. Putting this in binary, we get
0000000000000011 00000000010 00000As the CPU continues to request data, more cache lines are filled and more requests can be satisfied from cache.
A Cache Write: Eventually the CPU writes data to 196,668. Remember that this is the first address we read. Decoding the address, we find that we must look in cache line one. The tag bits in the address match, so our data is still in the cache. We write the new value to byte 28 in the cache line. What happens next depends upon the write policy of the cache system. If this is a write-through cache then we write the changed data to memory immediately. However, if this is a write-back cache (also called a "deferred write" cache) we set the dirty bit to one to indicate that the data in the cache no longer match memory, but we don't perform the write just yet.
Obviously a write-back cache can complete the CPU's request faster than a write-through cache because no memory access is needed -- yet. However, the write-through cache has advantages when I-O devices or other CPUs can access memory independent of this CPU. The choice of write policy depends upon the design of the overall system.
Another Read Request, and a Collision: After some time (maybe a few milliseconds) the CPU requests data from address 262,198. That's 40036 in hex. In binary, and spaced out according to the fields, it looks like this:
0000000000000100 00000000001 10110What happens next depends on the write policy of the cache. If it's a write-through cache, memory has already been updated with the results of any writes to the cache. If it's a write-back cache, we have to examine the dirty bit. If it's a one, the cache has been updated, but memory has not, and the cache line must be written to memory.
Then the 32 bytes of data at address 0000000000000100 00000000001 00000 are loaded into the cache line and byte 10110 is also passed to the CPU. The dirty bit is turned off and the valid bit is turned on. (It was already on, but it's faster just to set it than to check.) The tag field is set to 0000000000000100 and line one of the cache is ready to respond to addresses "near" 262,198.
This isn't usually as bad as it may sound. Because of temporal locality of reference by this time we are likely to be done with addresses near 196,668. The cache system is just keeping up with what's going on. (Note, however, that in some circumstances a program could be using data near both locations at the same time. In such a case, performance will be worse than if there were no cache.)
That completes our quick look at the operation of a cache memory. By now you have a better understanding of how a cache works. However, we blew by a few things that still need to be mentioned.
A Few Other Items...
How Fast is a Cache? After working your way through a few cache operations, you may wonder whether the improvement from a cache is worth the trouble. We can compute the average access time for a memory with a single-level cache.Let A be the average access time of the system including memory and cache. M is the access time of the main memory and C is the access time of the cache. The hit ratio, H is the percent of accesses that are satisfied from the cache. Hit ratios of 80 to 95% are not uncommon.
Given the above, we can derive the following formula:
Let's do an example. A memory system has a cache access time of 5ns, a main memory access time of 80ns, and a hit ratio of .94. Substituting into the formula we get
Remember this formula; you will need it on the exams.
What Happens on a Write-Miss In the example we talked about what happened when a write by the CPU "hit" a cache entry. We either wrote to both the cache and memory (write-through) or updated the cache and set the dirty bit to remind us to do the write later. (write-back.)
If the data were not in cache, our choices are simply to update memory and not worry about the cache, or to bring the block to be updated into cache and the proceed as above. The latter approach, bringing the data into cache, is called write-allocate.
Each approach has its advantages. As with other decisions, there are trade-offs and one must consider the system design as a whole.
A Set-Associative Cache It is obvious from the detailed example above that many areas of main memory can map to the same cache line. Where two (or more) such areas are active at the same time, performance can be worse than with no cache at all.
Consider what might happen if each cache line had two sets of fields: two valid bits, two dirty bits, two tag fields, and two data fields. One set of fields could cache data for one area of main memory, and the other for another area which happens to map to the same cache line. In order not to compromise speed, the comparison of the tag fields in the cache line with the tag part of the address must happen simultaneously. We can make that happen by providing two comparators. Such a simultaneous comparison is called associative and a cache built this way is called a set-associative cache. The "set" part means we still use a part of the address to determine which line to check, and the "associative" part means the checking is done simultaneously.
A set-associative cache with two sets of fields is a two-way set -associative cache. Four sets of fields makes a four-way set-associative cache.
Even with two or four sets of fields, sometimes there will be collisions. In a direct-mapped cache, there's no question about where to put the data because there's only one choice. In a set-associative cache, there may be two or four choices, and the cache subsystem has to decide.
One obvious approach would be to replace the least recently used entry, and some set-associative caches work that way. However, there's a lot of bookkeeping, and so a lot of circuitry, connected with keeping up with which entry is least recently used.
Surprisingly, just picking an entry at random works almost as well. With a two-way cache, a random choice is "right" about half the time, and the rest of the time the needed entry will be reloaded from memory on the next reference.
Fully Associative Caches If a two-way set-associative cache is good, a four-way cache is probably better. You might reason that eight-way is better than that. Hmmm... maybe we could get rid of the "line" idea altogether and make a 2048-way associative cache. Any block of data can go in any entry, and they're all searched simultaneously. Such a cache is called a fully-associative cache. The number of simultaneous comparisons is now 2048 instead of two or four, and the bookkeeping needed for keeping track of the least recently used entry of 2048 possibilities is too complex to be practical.
Although fully-associative caches are a theoretical possibility, set-associative caches are used in the real world. In fact, it is rare to find a cache of degree of associativity greater than four.
Separate Caches for Instructions and Data: A single cache such as we have discussed is called a unified cache. It is possible to design a system with two
cache memories, one for instructions, driven by the program counter, and one for data, driven
by data requests from the CPU. Such a cache can offer performance improvements. It is called
a split cache.
Please take a moment to
References
[TANE99] Tanenbaum, Andrew S., Structured Computer Organization, Prentice-Hall, 1999.
Originally published: 2000-10-28
Copyright © by Bob Brown. Some rights reserved.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
Last updated: 2014-10-02 7:17